Today marks the opening in Siena of the international conference Digital Heritage 2025, the largest international event dedicated to research on information technologies applied to the documentation, preservation, and sharing of cultural heritage.
CRS4 is taking part in the event with two scientific contributions, presented by Ruggero Pintus and Fabio Bettio from the Visual and Data Intensive Computing sector:
-
A Practical Inverse Rendering Strategy for Enhanced Albedo Estimation for Cultural Heritage Model Reconstruction (Pintus, R., Zorcolo, A., Jaspe Villanueva, A., Gobbetti, E., Proc. Digital Heritage 2025. DOI: 10.2312/dh.20253025).
Developed in collaboration with KAUST, this paper introduces a method that significantly improves color accuracy in flash photography acquisitions of 3D objects. The technique has already been applied to the documentation of the Mont’e Prama statues. The work is presented in the Acquisition and Digitization session. -
OpenLIME: An open and flexible web framework for creating and exploring complex multi-layered relightable image models (Ponchio, F., Bettio, F., Marton, F., Pintus, R., Righetto, L., Giachetti, A., Gobbetti, E., Proc. Digital Heritage 2025. DOI: 10.2312/dh.20253240).
This contribution presents OpenLIME, an open and flexible framework for creating and exploring complex multi-layered, relightable image models. Developed in collaboration with ISTI-CNR, it has already been used in several research and dissemination projects, including the virtual musealization of Costantino Nivola’s Sandcast Olivetti. The work is presented in the Visualization and Interaction session.
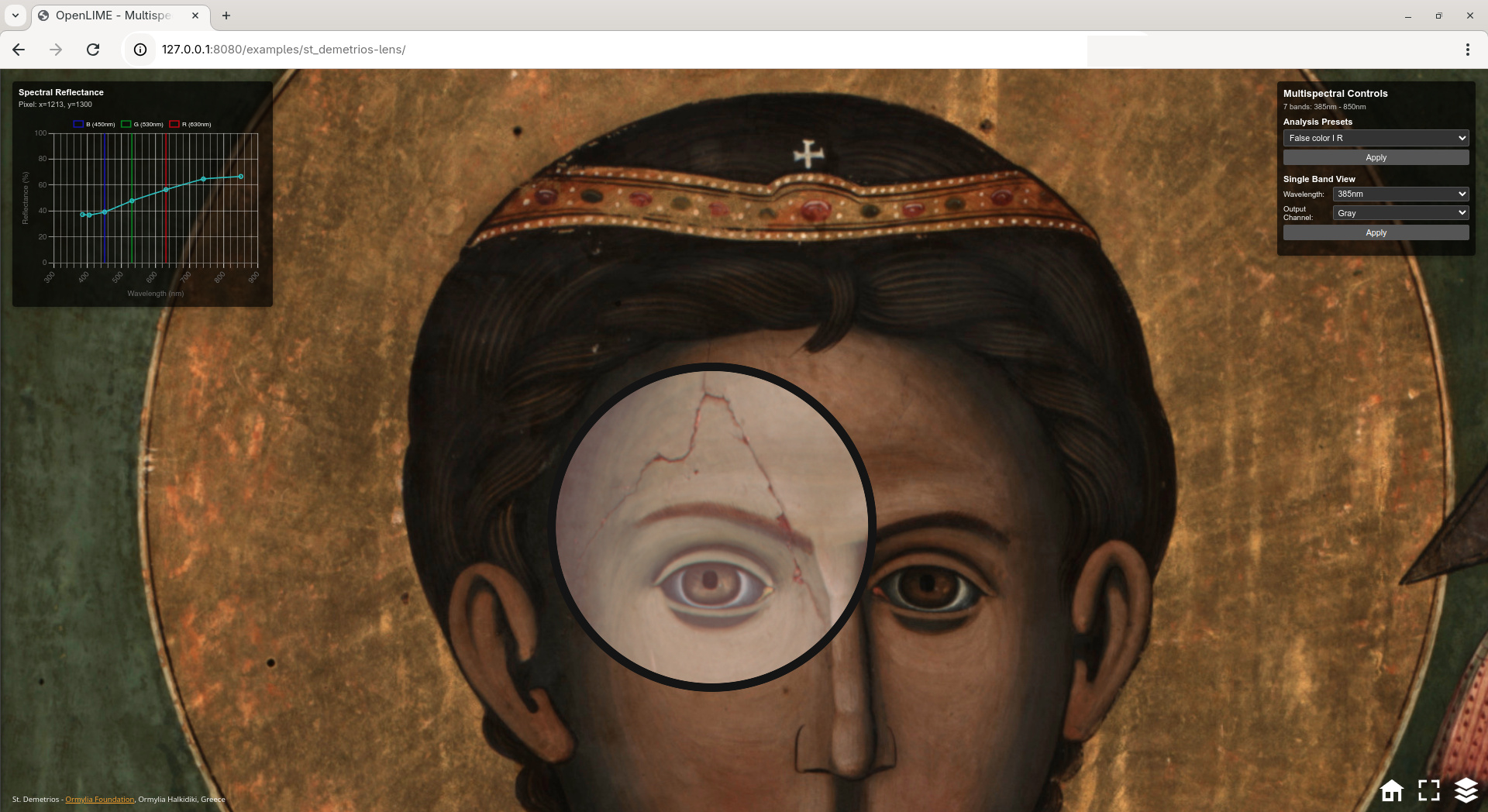
The image shows the multilayered multispectral visualization of a Saint Demetrios icon. The model represents the 7-band albedo obtained from 50 photographs captured under UV (385 nm, 405 nm), visible (RGB), and infrared (740 nm, 850 nm) directional lighting. The graph displays the multispectral reflectance of a selected skin pixel. The lens highlights the False Color Infrared mode (R=IR-850nm, G=VIS-R, B=VIS-G), while the context shows the visible channels.






